Vector Embedding
들어가며
머신러닝에서 벡터 임베딩(Vector Embedding)은 데이터를 수치 공간으로 옮겨,
컴퓨터가 의미적으로 비교할 수 있게 만드는 핵심 개념이다.
특징(feature)를 추출하는데에 쓰인다고 볼 수도 있고, 그에 따른 용도가 굉장히 많다.
이 글에서는
1) 임베딩의 기본 개념
2) CLIP ViT-B/32 모델 소개 (DINOv2, RN50과 비교)
3) 임베딩을 실제로 어떻게 활용할 수 있는지
를 중심으로 정리해본다.
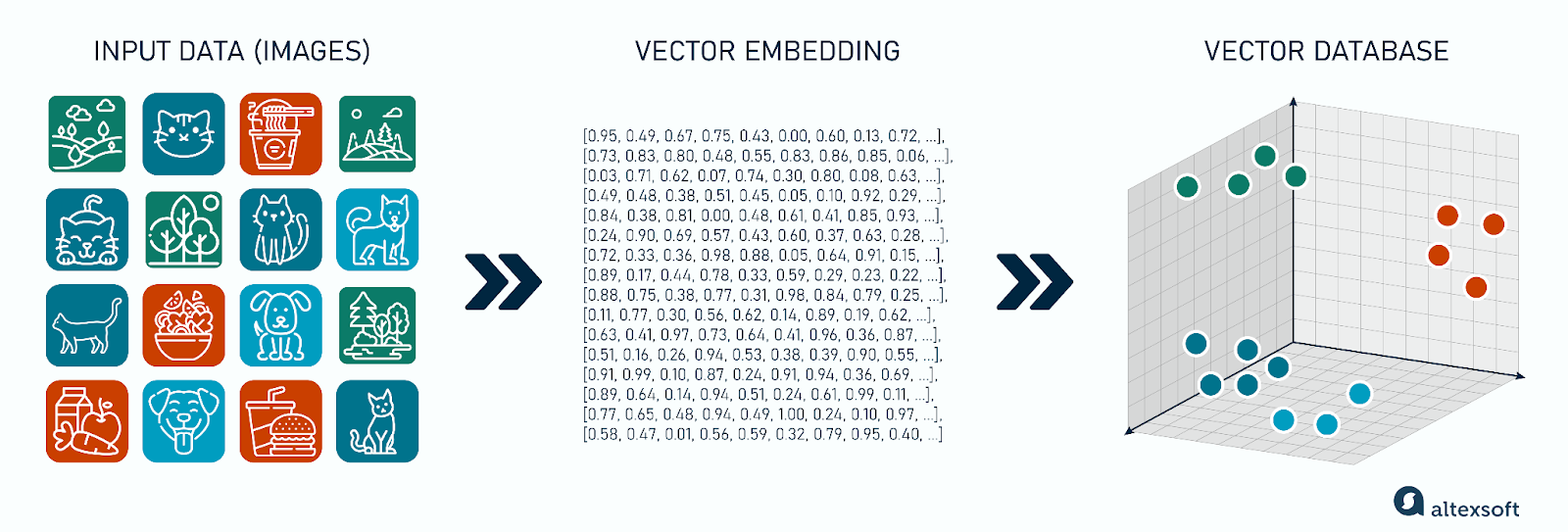
벡터 임베딩(Vector Embedding)이란?
이 이미지는 인턴십 마무리 발표 때 자료에 넣었다가 분량 문제로 영영 삭제당한 비운의 이미지이다…
임베딩에 대해 잘 모른다면 이해에 도움이 되는 좋은 자료라고 생각해서 넣어보았다.
임베딩은 텍스트나 이미지 같은 데이터를 고정 길이의 실수 벡터로 변환하는 것이다.
즉, -1부터 1 사이의 숫자들의 리스트라고도 할 수 있는데 이 리스트의 길이가 즉 차원수가 된다.
이 벡터는 데이터의 의미적·시각적 특징을 압축해서 담고 있다.
리스트의 각 자리(차원)가 정확히 어떤 특징에 대한 정보를 담게 되는지는 모델마다, 그리고 학습에 사용한 데이터셋에 따라 달라지기 때문에 정확히 정의내릴 수는 없으며, 한가지 특징이 여러 차원에 걸쳐 표현되기도 한다.
중요한 점은, 임베딩 공간에서는 비슷한 정도(유사도)를 거리로 표현할 수 있다는 것이다.
유사도 관점에서의 임베딩
임베딩 벡터들 사이의 관계는 보통 Cosine 유사도(cosine similarity)로 계산한다.
- 값이 1에 가까울수록 매우 유사
- 0에 가까우면 관련성 낮음
- 음수면 반대 성향
이 덕분에 임베딩은 검색, 클러스터링, 분류, 이상 탐지등 다양한 작업에 바로 활용할 수 있다.
CLIP 모델 개요
CLIP (Contrastive Language–Image Pretraining)은
이미지와 텍스트를 같은 벡터 공간으로 매핑하도록 학습된 멀티모달 모델이다.
즉,
- 이미지를 벡터로
- 텍스트를 벡터로 변환한 뒤, 둘의 유사도를 직접 계산할 수 있다.
이 구조 덕분에 CLIP은 다음과 같은 특징을 가진다.
- 이미지–텍스트 간 유사도 계산 가능
- 별도 fine-tuning 없이도 꽤 강력한 zero-shot 성능
- “이 이미지가 어떤 설명과 가장 잘 맞는가?” 같은 문제에 적합
CLIP ViT-B/32 소개
CLIP은 여러 backbone을 지원하는데,
그중 ViT-B/32는 실무에서 많이 쓰이는 균형형 모델이다.
ViT-B/32란?
- ViT (Vision Transformer) 구조
- Base 크기 모델
- 32×32 패치 단위로 이미지를 처리
특징은 다음과 같다.
- ResNet 기반 모델 대비 구조가 단순
- 연산량 대비 성능이 안정적
- 대규모 배포 환경에서도 부담이 적음
하나 더 신기한 점이 있다면 CLIP은 단순히 이미지만 넣고 학습시킨게 아니라 인터넨 상의 엄청난 양의 이미지와 텍스트를 한 쌍으로 같이 넣고, 관련이 없는 이미지와 텍스트의 코사인 거리는 멀어지고, 관련이 깊은 이미지와 텍스트의 벡터공간상 코사인 거리는 가까워지도록 학습시켜, 텍스트를 통해 이미지를 검색하는 것도 가능하다.
다른 임베딩 모델과의 비교
CLIP ViT-B/32 vs RN50
| 항목 | RN50 | ViT-B/32 |
|---|---|---|
| 구조 | CNN | Transformer |
| 학습 방식 | CLIP | CLIP |
| 특성 | 로컬 특징 강함 | 전역 의미 표현에 유리 |
| 실무 사용성 | 안정적 | 범용성 높음 |
CLIP vs DINOv2
DINOv2는 self-supervised 방식으로 학습된 비전 모델이다.
- 이미지 표현 품질이 매우 뛰어남
- 클러스터링, 시각적 유사성 분석에 강함
- 텍스트와 직접 연결되지는 않음
정리하면:
- 텍스트까지 함께 쓰려면 → CLIP
- 이미지 자체 표현 품질이 중요하면 → DINOv2
임베딩을 어떻게 써먹을 수 있을까?
1. 유사도 검색 (Similarity Search)
가장 대표적인 활용이다.
- 모든 데이터를 임베딩으로 변환
- 쿼리 입력도 임베딩
- 가장 가까운 벡터를 찾음
이미지 검색, 문서 검색, 추천 시스템의 핵심 구조가 여기에 해당한다.
FAISS(페이스북에서 만든 벡터 DB) 같은 라이브러리를 함께 사용해 대규모 검색을 처리한다. 내가 회사에서 일할 때에는 일반적으로 항상 Elasticsearch를 사용했었던 걸 보면 es도 보편적인 선택지로 보인다.
- 기존 검색/로그 인프라와 자연스럽게 통합 가능
- kNN 검색(Dense Vector) 기능 지원
- 텍스트 검색(BM25)과 벡터 검색을 함께 사용하는 하이브리드 검색 구성 가능
이 때문에 이미 Elasticsearch를 사용 중인 조직에서는,
별도의 벡터 DB를 도입하기보다 Elasticsearch를 활용해 임베딩 검색을 구성하는 선택을 하기도 한다.
2. 이상 데이터 탐지 (Anomaly Detection)
임베딩 공간에서 정상 데이터는 특정 영역에 밀집되는 경향이 있다.
이와 멀리 떨어진 벡터는 이상 데이터로 판단할 수 있다.
- 평균 벡터와의 거리
- 클러스터 중심과의 거리
- 최근 데이터 분포와의 차이
이런 방식으로 간단한 이상 탐지가 가능하다.
3. 텍스트 기반 이미지 검색 (CLIP의 강점)
CLIP을 사용하면 텍스트로 이미지를 검색할 수 있다.
예를 들어:
- “사람이 없는 도로”
- “눈이 많이 쌓인 풍경”
같은 문장을 임베딩한 뒤, 이미지 임베딩과 비교한다. 이 방식은 별도의 라벨 없이도 꽤 직관적인 검색 결과를 만들어낸다.
마무리
초기에 ML 관련된 쪽으로는 아예 관심이 없었을 때 임베딩을 접하게 됐을 때는 그냥 비슷한 이미지(과자봉지를 보고 무슨 과자인지 맞추는 용도로 썼었다..)를 찾아주는 신기하지만 뭔가 믿음직스럽지 않은 무언가였었다. 그러다 어쩌다 좋은 기회로 임베딩을 좀 더 깊게 다뤄볼 기회가 생겼는데, 동일한 입력을 넣으면 동일한 결과가 나오는 하나의 인코딩 방법으로서 임베딩은 사용자가 사용하는 방법에 따라서 얼마든지 신뢰성 있게 사용될 수 있는 검색, 분류, 탐지의 출발점인 것 같다.
CLIP ViT-B/32는
- 이미지와 텍스트를 함께 다뤄야 하는 상황에서
- 성능과 비용의 균형이 필요한 경우 에서 크게 부담없이 사용하기 좋은 모델이었다.
라고 말은 했지만… 비교적 얕은 수준에서 해본 정도라고 생각한다. 계속 배우면서 보충하도록 하겠다…